Introduction
When working with bigger software systems, it’s easy to get lost in all the source code that makes up the system. A good software system has to provide a structure that allows developers to quickly grasp the main ideas of a system. A proven method to achieve this is using hierarchies and schemas. With this approach, tiny things can be summed up to bigger ones that make somehow sense in a more broader view.
Schemas are conceptual units humans can reason about because they are familiar with it. If I say “school”, you can quickly link some memories to that conceptual unit and attach new information to it. If I had started with all the details about my specific school – the building, my teachers, my pencil, every insignificance – without mentioning “school” at all, you wouldn’t be able to follow my thoughts at all.
Hierarchies are built upon conceptual units that are linked together in a tree-like structure. Conceptual units are part of multiple hierarchies depending on your perspective: In the example above, I’m speaking from the perspective of a pupil. But if you are an architect, you see the “building” school. If you are the school’s district manager, you see it as a cost center.
So there are multiple hierarchies, building up multiple schemas as well, leading to a more graph-like structure of the things we know. With these methods, we can produce nice little information packages (aka chunks) that are consumable way easier. And small is good! It’s exactly what we need to process information quickly as well. Otherwise, we would be overwhelmed by pure information overload.
Implementing hierarchies and schemas for source code
Moving this view to software development, we see that there is a need for building up higher-level abstractions out of source code. We try to do it by creating a software architecture where its component are ordered in a hierarchical way. In most programming languages, this is will be directories and files in the end. For example, translated into the Java world, it means packages and source code files.
But there is a big problem with this approach: Those hierarchies are one-dimensional. But you have multiple views on your application:
- If you use the model view controller pattern, you see your components, well, as models, views and controllers.
- If you want to add new business features, you see it divided into the subdomains of your business domain.
- If you look at it from a performance’s perspective, you see slow components, clients for external systems or database access components.
- If you look at the code contributions of developers, you’ll see different areas of code maintained by different teams.
- If you are interested in the stable parts of your system, you will examine all the changes in a version control system.
This “multiperspectivity” can’t be expressed in source code directly. This also means that building up those hierarchies and schema for easier information processing isn’t possible at all. This makes it so hard to understand and reason about all the interconnected, multifaceted problems in your application – making problem-solving harder than it has to be.
Luckily, there are tools to reduce this ubiquitous problem in software development. Carola Lilienthal wrote about SotoGraph in her book and Adam Thornhill will address this in his upcoming book as well. I want to show you an additional possibility based on jQAssistant and Neo4j. I wrote about my experience with this structural analysis tool in My Experiences with jQAssistant a while ago. Here I just scratched the surface regarding the main reasons why I like that tool so much: It is capable of creating different perspectives on your software system by using hierarchies (by using nodes and relationships) and schemas (via “concepts”). This is an extremely powerful way to abstract all software entities in your software to entities that software architects or even business expert can understand and thus reason about.
Let’s have a look how this works!
Example 1: Technical Concepts
If we take a look at the living architecture documentation in jqassistant/structure.adoc of the jQAssistant’s version of Spring Petclinic, we can see that jQAssistant can mark software entities (in this case Java types) depending on their relationship to other software entities:
[[spring-mvc:Controller]]
[source,cypher,role="concept"]
.Labels all types annotated with "org.springframework.stereotype.Controller"
with "Spring", "Component" and "Controller".
----
MATCH
(controller:Type)-[:ANNOTATED_BY]->()-[:OF_TYPE]->(annotationType:Type)
WHERE
annotationType.fqn = "org.springframework.stereotype.Controller"
SET
controller:Spring:Component:Controller
RETURN
controller as Controller
----In the case above, jQAssistant assigns the labels Spring, Component and Controller to every entity in the software system that is annotated with the annotation’s type org.springframework.stereotype.Controller. A Controller is a high-level technical concept as described above. Once marked in the database, you can find all other controllers as well and ask specific questions / create queries about them in a clear context. The marking mechanism gives you many different options for labeling and thus reason about all the technical entities in your software system.
Example 2: Business Subdomains
But often, business people don’t want to talk about all the technical details like “controllers”. We as software developers have to create other higher-level abstractions that mean something to non-technical people. In Analyze Dependencies Between Business Subdomains, I sketched a way how you can achieve this based on package naming conventions. But as mentioned above, there are multiple ways how you can structure your software system. This means that relying on package naming conventions couldn’t be possible.
But even if there aren’t any package naming conventions, you can identify some structure for example in class names or in your inheritance hierarchy that points you towards your subdomains in the code (if that isn’t possible as well: I wrote my Master’s thesis about mining cohesive concepts from source code via text mining, so you could use that as well 😀 . There are also many other possibilities. And at the last resort, you have to do the mapping manually…).
Let’s see how this could work by mapping business subdomains to the class names of the Spring PetClinic project that we used above. In this project, the Java types look like this:
EntityUtilsOwnerControllerPetRepositoryJpaVetRepositoryImplPetNamedEntityJpaVisitRepositoryImplVisitControllerPetTypeFormatter
From the random list above, you can see that the names contain some information about the subdomain of the application like “Pet”, “Owner” or “Visit”. With a simple heuristic, we can map predefined subdomain names with the names of Java types by naming conventions. E. g. a rule in your living architecture documentation could be like this one:
The Spring PetClinic application consists of several business subdomains that can be identified by naming conventions.
[[business:Subdomain]]
.Create predefined Subdomain nodes and connect them to all Type nodes by naming conventions
[source,cypher,role=concept]
----
UNWIND [
{ name: "Clinic" },
{ name: "Owner" },
{ name: "Person" },
{ name: "Pet" },
{ name: "Specialty" },
{ name: "Vet" },
{ name: "Visit" }
]
AS properties
CREATE (s:Subdomain) SET s = properties
WITH s
MATCH (t:Type)
WHERE t.name CONTAINS s.name
MERGE (t)-[:BELONGS_TO]->(s)
RETURN s.name, t.name
----Here, we first predefine all business subdomains as a map of properties and add new nodes for them. Additionally, we connect all the types that belong to a subdomain via the naming convention. In the database, we have now the information about the subdomain for each type in our software. The blue colored nodes are the Type nodes of the software system that are connected by a BELONGS_TO relationship to the grey node in the middle which is one of the Subdomain nodes.
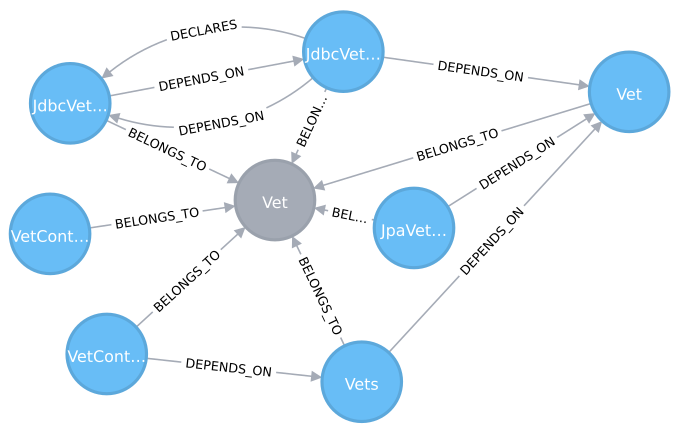 We can refine this model by adding information as we like and as long as there is some structural information existing for the data sources. For example, if we use the code analysis tools like FindBugs, it’s possible to add existing coding violations into the graph and connect them to the types – and thus the subdomains. If we are using a bug tracking system like Bugzilla, we can list known bugs for specific subdomains. This enables us to look at internal code quality from a business’ perspective! The problem space is reduced and can be communicated in a language that can be understood by business people as well.
We can refine this model by adding information as we like and as long as there is some structural information existing for the data sources. For example, if we use the code analysis tools like FindBugs, it’s possible to add existing coding violations into the graph and connect them to the types – and thus the subdomains. If we are using a bug tracking system like Bugzilla, we can list known bugs for specific subdomains. This enables us to look at internal code quality from a business’ perspective! The problem space is reduced and can be communicated in a language that can be understood by business people as well.
This is the entry point into “software triage” which can help to focus on effective refactoring or reengineering tasks!
Summary
In this blog post, you saw how you can create higher-level abstractions of your source code. With this approach, you can create schemas of known things by marking them either by additional node labels or by creating new conceptual nodes. Both approaches are fine to create more sophisticated hierarchies leading to chunks of information that can be processed by people who are unfamiliar with all the details of a software system. This enables discussions on a new level!
By focusing on hierarchies that mean something to business people, a software architect can now discuss issues in the software system in terms of the business. With the graph-based approach in Neo4j, you can easily add additional information about open bug tickets, static code analysis results, latest code changes – everything! Discussions about code quality don’t start with general statements like
“Ohhh, we are doomed, because we have so much technical debt!”
or on a very detailed perspective like
“AbstractNotificationProxyServiceManager has a cyclomatic complexity of 144!”
but on the right level:
“If you plan to change the notification feature in the next sprint, be sure to add additional time for cleaning up the code base for this component.”
where you can go deeper if needed e. g. with
“There are 4 open bugs and the code is more complex than it has to be. Ohh, and the main developer leaves the company in three weeks, so it should be a high priority user story in your backlog as well!”
I hope you can imagine the potential of higher-level abstractions of your source code. It’s a very context-dependent approach that requires some customization because every business domain and thus software system is different. But that’s exactly the reason why it is so powerful: It works in your context and it’s tailored to your specific needs!
What do you think about it? Are there any barriers that are still in the way? What are your ideas to bring developers and business people together to talk about internal software quality on the same level?
Pingback:A graph(ical) approach towards Bounded Contexts – feststelltaste