TL;DR I generate a big amount of fake data for Spring PetClinic with Faker that I store directly in a MySQL database via Pandas / SQLAlchemy.
Introduction
In preparation for a talk about performance optimization, I needed some monstrous amounts of fake data for a system under test. I choose the Spring Pet Clinic project as my “patient” because there are some typical problems that this application does wrong. But this application comes with round about 100 database entries. This isn’t enough at all.
So in this notebook, I’ll show you how to
- examine the existing database tables
- generate some fake data
- initializing a database schema
- dumping all data into the database
And of course: How to do that very efficiently with the Python Data Analysis Library aka Pandas and some other little helpers.
We will also be playing a little around to get an impression where to get some other fake data, too!
Hint: This notebook is also available on GitHub.
Context
The Spring PetClinic software project is a showcase example for the Spring framework. It comes with a nice little Web UI and a backend written in Java. The documentation says
The application requirement is for an information system that is accessible through a web browser. The users of the application are employees of the clinic who in the course of their work need to view and manage information regarding the veterinarians, the clients, and their pets.
The application stores some data into a database:
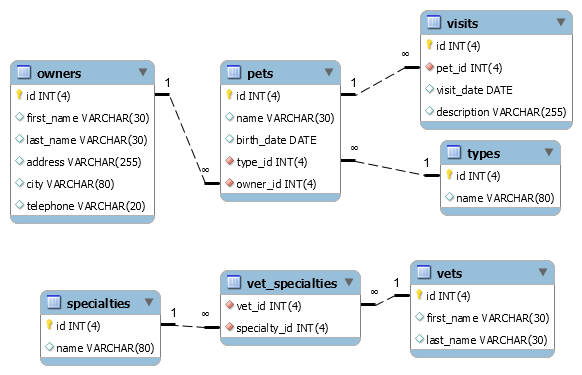
There are some issues with the application while accessing the data, but I won’t get into this in this notebook. Instead, I will focus on the data generation for all these tables. My approach here is straightforward: I adopt the existing tables with their data types and constraints, delete existing data and inserts some new data into the existing tables. Hereby I respect the generation of unique primary keys and foreign keys by the means of Pandas’ abilities. We also have to keep the right insertion order in mind. There are some tables that depend on already existing data from other tables. But I will get into details later.
Configuration
At the beginning, one can define the amount of data that should be created and be stored in the database. We don’t need it yet, but I find it always nice to have the parameters that can be change at the beginning of a notebook. The configuration is then printed out. Let’s produce some production data!
AMOUNT_VETS = 1000
AMOUNT_SPECIALTIES = 2 * AMOUNT_VETS
AMOUNT_OWNERS = 10 * AMOUNT_VETS
AMOUNT_PETS = 2 * AMOUNT_OWNERS
AMOUNT_PET_TYPES = int(AMOUNT_PETS / 10)
AMOUNT_VISITS = 2 * AMOUNT_PETS
print("""
Generating fake data for
- %d vets,
- each having ~%d specialties,
- each for serving ~%d owners,
- each caring for ~%d pets,
- of max. ~%d types/races and
- each taking them to ~%d visits.
""" % (AMOUNT_VETS, AMOUNT_SPECIALTIES, AMOUNT_OWNERS, AMOUNT_PETS, AMOUNT_PET_TYPES, AMOUNT_VISITS))
Examine the database schema
Connect to the database
This step usually occurs at the end of a script, but in this notebook, I want to show you how the tables are made up. So simply create a database connection with SQLAlchemy and the underlying MySQL Python Connector:
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqlconnector://root:admin@localhost:3306/petclinic', echo=False)
engine.driver
Inspect the schema
SQLAlchemy brings a great tool for inspecting the database: The Inspector.
from sqlalchemy.engine import reflection
insp = reflection.Inspector.from_engine(engine)
insp.default_schema_name
The Inspector allows us to iterator over various data of the schema:
relevant_methods = [x for x in dir(insp) if x.startswith("get")]
relevant_methods
So for example you, can easily lists all tables:
insp.get_table_names()
With the Inspector from SQLAlchemy, we can easily list the needed data types for the table:
import pandas as pd
pd.DataFrame(insp.get_columns('owners'))
Data generation
Fake data in general
We could just fill up the data randomly, but I want to show you, how to get some real looking data. For this, nice little helpers are out there for implementing that. In this notebook, I use the fake data provider Faker (https://github.com/joke2k/faker). It comes with nice helper methods for generating data:
from faker import Factory
fake = Factory.create()
fake.name()
fake.street_address()
fake.phone_number()
But there is one drawback: Faker doesn’t seem to be appropriate for generating massive amount of test data. For example, on my machine (Lenovo X220 i5) it takes almost 5 seconds to generate 100k phone numbers.
%%time
[fake.phone_number() for _ in range (1,100000)]
_
While this is no problem for our little scenario, there could be room for performance improvement (and I’ve already programmed a prototype, stay tuned!).
But let’s get back to our original task: Generating fake data for Spring PetClinic!
Fake “Owners”
So, for the table for all the pet’s owners, we need a DataFrame that looks like this one:
# just some unreadable code to make a point
pd.DataFrame(columns=pd.DataFrame(insp.get_columns('owners'))[['name']].T.reset_index().iloc[0][1::]).set_index('id')
In other words: We need a set of Series objects that we fill up with data that makes sense for each column. OK, let’s rebuild it step by step (or better to say: column by column). To keep it simple, we ignore the database specific data types in this example.
The first trick is to fill the index (the later “id” column aka primary key) with the amount of data that is requested. We set the amount already at the beginning of the notebook and simply use it here. We use the built-in range method for generating a continuous stream of numbers from 1 to the requested number of owners +1. We need to shift the lower and upper bound because the primary keys for our database starts at 1.
owners = pd.DataFrame(index=range(1,AMOUNT_OWNERS+1))
owners.head()
Next, we set the name of the index column to id. This is just a minor correction to store the data more easily in the database later on.
owners.index.name='id'
owners.head()
Alright, let’s generate some first names with Faker. We sample via the map function of the index (which is not very performant, but will do for now).
owners['first_name'] = owners.index.map(lambda x : fake.first_name())
owners.head()
We repeat that for all the other columns with the appropriate data.
owners['last_name'] = owners.index.map(lambda x : fake.last_name())
owners['address'] = owners.index.map(lambda x : fake.street_address())
owners['city'] = owners.index.map(lambda x : fake.city())
owners['telephone'] = owners.index.map(lambda x : fake.phone_number())
owners.head()
The generation of this table was very easy. Let’s see what’s next!
Fake “Types” (of a pet)
Each owner has a pet of a specific type.
pd.DataFrame(insp.get_columns('types'))
So we need a DataFrame like this:
# just some unreadable code to make a point
pd.DataFrame(columns=pd.DataFrame(insp.get_columns('types'))[['name']].T.reset_index().iloc[0][1::]).set_index('id')
We need some animal names for generating the pet’s type table. Unfortunately, Faker doesn’t provide such data. Luckily, after one Google search, someone placed a list of animals on the World Wide Web. We just read that data with Pandas as an index.
Note: We could have written our own specific provider for fake data, but that too much for this notebook.
Side note: I took not the raw data GitHub provides and saved it locally with a reference to the original origin (as you normally should do), but instead took the HTML pages just because I can 🙂
# loads all HTML tables from the site, but take only the first found and the second column
animal_names = pd.read_html("https://github.com/hzlzh/Domain-Name-List/blob/master/Animal-words.txt")[0][[1]]
# set the ony column as index
animal_names = animal_names.set_index(1)
# remove the index name
animal_names.index.name = None
animal_names.head()
Now, we are getting to a key trick in generating data very efficiently: Vector operations. We have a DataFrame only consisting of an index column. Mathematically speaking, it’s a one-dimensional vector. Pandas (respectively the underlying Numpy library) is very efficient in working with these kinds of data.
There exist multiple operations that support working on vectors. What we need is to get a random amount of entries from a given data set, which is called “sampling”. Pandas DataFrame provides such a sampling function to achieve that. We use sampling to draw some entries from the animals’ data set, e. g. three different kinds:
animal_names.sample(3)
OK, lets’ get back to the types table. We generate the index first. Here we have to be careful: It could be that one requests more pet types as there are in the animal_names dataset, but we don’t want to allow duplicates. So we limit the index with a min-function if the requested number of animals exceeds the number of animals avaliable.
types = pd.DataFrame(index=range(1, min(AMOUNT_PET_TYPES, len(animal_names))+1))
types.index.name='id'
types.head()
Now we draw the animals from animal_names. We sample the number of requested pet types at once from the animal_names‘ index.
types['name'] = animal_names.sample(len(types)).index
types.head()
And that’s all fake data for the pet types.
Fake “Pets”
Let’s get back to some more easy data: The Pets.
pd.DataFrame(insp.get_columns('pets'))
We need some fake data and some ids to already existing entries from the two tables owners and types.
Let’s see if we can get some nice data looking like that Dataframe here:
# just some unreadable code to make a point
pd.DataFrame(columns=pd.DataFrame(insp.get_columns('pets'))[['name']].T.reset_index().iloc[0][1::]).set_index('id')
pets = pd.DataFrame(index=range(1,AMOUNT_PETS+1))
pets.index.name='id'
pets['name'] = pets.index.map(lambda x : fake.first_name())
pets['birth_date'] = pets.index.map(lambda x : fake.date())
pets.head()
For the ids to the owners and types table, we use the sampling function that I’ve introduced above to draw some ids. The important different is, that we set an additional argument replace=True, which is necessary when more samples should be drawn than data entries are available in the dataset. Or in plain English: If duplicates should be allowed. This makes perfect sense: One owner can own more than one pet of different kinds/types.
pets['type_id'] = types.sample(len(pets), replace=True).index
pets['owner_id'] = owners.sample(len(pets), replace=True).index
pets.head()
Fake “Visits”
The next few tables are straightforward.
pd.DataFrame(insp.get_columns('visits'))
visits = pd.DataFrame(index=range(1,AMOUNT_VISITS+1))
visits.index.name='id'
visits['pet_id'] = pets.sample(len(visits), replace=True).index
visits['visit_date'] = visits.index.map(lambda x : fake.date())
# just add some random texts
visits['description'] = visits.index.map(lambda x : fake.text())
visits.head()
Fake “Vets”
pd.DataFrame(insp.get_columns('vets'))
vets = pd.DataFrame(index=range(1,AMOUNT_VETS+1))
vets.index.name='id'
vets['first_name'] = vets.index.map(lambda x : fake.first_name())
vets['last_name'] = vets.index.map(lambda x : fake.last_name())
vets.head()
Fake “Specialties”
pd.DataFrame(insp.get_columns('specialties'))
specialties = pd.DataFrame(index=range(1,AMOUNT_SPECIALTIES+1))
specialties.index.name='id'
specialties['name'] = specialties.index.map(lambda x : fake.word().title())
specialties.head()
Fake “Vet_Specialties”
OK, this table is special and worth a few words.
pd.DataFrame(insp.get_columns('vet_specialties'))
It’s a many to many join table between the vets table and the specialties table. So we need a table that has the connections to the ids of both tables with the appropriate length “n x m”. But there is a catch that we have to address later, this is why I use a temporary (“tmp”) DataFrame:
vet_specialties_tmp = pd.DataFrame(
index=specialties.sample(
len(vets)*len(specialties),
replace=True).index)
vet_specialties_tmp.index.name = "specialty_id"
vet_specialties_tmp.head()
For all specialties, we assign vets.
vet_specialties_tmp['vet_id'] = vets.sample(len(vet_specialties_tmp), replace=True).index
vet_specialties_tmp.head()
We set the ids of the vets as the index, too.
vet_specialties_tmp = vet_specialties_tmp.set_index([vet_specialties_tmp.index, 'vet_id'])
vet_specialties_tmp.head()
Now we have to make sure, that we don’t have duplicates in the dataset. We take only the unique index entries and create the actual vet_specialties DataFrame with the right index names.
vet_specialties = pd.DataFrame(index=pd.MultiIndex.from_tuples(vet_specialties_tmp.index.unique()))
vet_specialties.index.names =["specialty_id" , "vet_id"]
vet_specialties.head()
And we’re almost done! So far it seems like a brainless activity in most cases…maybe we can automate that in the future 😉
Store the data
Now we store the generated data in the database.
Remove old data
Before we insert the data, we clean up the existing database by dropping all the tables with all the existing data. We have to do that in the right order to avoid violating any constraints.
drop_order = [
"vet_specialties",
"specialties",
"vets",
"visits",
"pets",
"owners",
"types"
]
with engine.connect() as con:
for table in drop_order:
con.execute("DROP TABLE IF EXISTS " + table + ";")
Prepare the database schema
We execute the init script that comes with the Spring PetClinic project to get a shiny new database. For this, we read the original file via Pandas read_csv method and make sure, that we break the statements as needed.
init_db = pd.read_csv("data/spring-petclinic/initDB.sql", lineterminator=";", sep="\u0012", header=None, names=['sql'])
init_db['sql'] = init_db['sql'].apply(lambda x : x.replace("\r", "").replace("\n", ""))
init_db.head()
Then we execute all statements line by line via SQLAlchemy.
with engine.connect() as con:
init_db['sql'].apply(lambda statement : con.execute(statement))
Store the new data
Last but not least, here comes the easy part: Storing the data. We’ve modeled the DataFrames after the existing tables, so we don’t face any problems. The short helper function store avoids heavy code duplication. In here, we use the if_exists="append"-Parameter to reuse the existing database schema (with all the original data types, constraints and indexes). To send data on chunks to the database, we add chunksize=100.
def store(dataframe, table_name):
dataframe.to_sql(table_name, con=engine, if_exists="append", chunksize=100)
store(owners,'owners')
store(types, 'types')
store(pets, 'pets')
store(visits, 'visits')
store(vets, 'vets')
store(specialties, 'specialties')
store(vet_specialties, 'vet_specialties')
Summary
OK, I hope I could help you to understand how you can easily generate nice fake data with Pandas and Faker. I tried to explain the common tasks like generating data and connecting tables via foreign keys.
Please let me know if you think that there is anything awkward (or good) with my pragmatic approach.