Introduction
In this blog post, I want to show you how you can visualize the contributions of developers to your code base over time. I came across the Stream Graph visualization and it looks like it would fit quite nicely for this purpose. Fortunately, there is already a D3 template by William Turman for this that I use in this blog post:
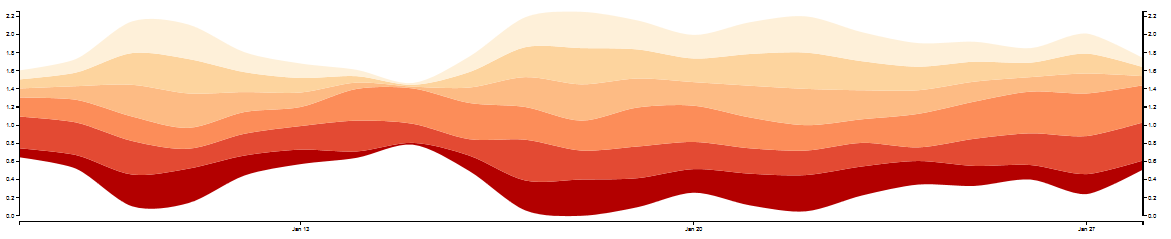
So let’s prototype some visualizations!
Getting the data
At the beginning, we declare some general variables for easy access and to reuse them for other repositories easily.
PROJECT = "intellij-community"
SOURCE_CODE_FILE_EXTENSION = ".java"
TIME_FREQUENCY = "Q" # how should data be grouped? 'Q' means quarterly
FILENAME_PREFIX = "vis/interactive_streamgraph/"
FILENAME_SUFFIX = "_" + PROJECT + "_" + TIME_FREQUENCY
In this example, I’m using the rather big repository of IntelliJ which is written in Java.
We import the existing Git log file with file statistics that was generated using
git log --numstat --pretty=format:"%x09%x09%x09%h%x09%at%x09%aN" > git_numstat.log
import pandas as pd
logfile = "../../{}/git_numstat.log".format(PROJECT)
git_log = pd.read_csv(
logfile,
sep="\t",
header=None,
names=[
'additions',
'deletions',
'filename',
'sha',
'timestamp',
'author'])
git_log.head()
The logfile contains the added and deleted lines of code for each file in each commit of an author.
This file has over 1M entries.
len(git_log)
The repository itself has over 200k individual commits
git_log['sha'].count()
and almost 400 different contributors (Note: I created a separate .mailmap file locally to avoid multiple author names for the same person)
git_log['author'].value_counts().size
We mold the raw data to get a nice list of all committed files including additions and deletions by each author. You can find details about this approach in Reading a Git repo’s commit history with Pandas efficiently.
commits = git_log[['additions', 'deletions', 'filename']]\
.join(git_log[['sha', 'timestamp', 'author']]\
.fillna(method='ffill'))\
.dropna()
commits.head()
We further do some basic filtering (because we only want the Java source code) and some data type conversions. Additionally, we calculate a new column that holds the number of modifications (added and deleted lines of source code).
commits = commits[commits['filename'].str.endswith(SOURCE_CODE_FILE_EXTENSION)]
commits['additions'] = pd.to_numeric(commits['additions'], errors='coerce').dropna()
commits['deletions'] = pd.to_numeric(commits['deletions'], errors='coerce').dropna()
commits['timestamp'] = pd.to_datetime(commits['timestamp'], unit="s")
commits = commits.set_index(commits['timestamp'])
commits['modifications'] = commits['additions'] + commits['deletions']
commits.head()
The next step is optional and some basic data cleaning. It just filters out any nonsense commits that were cause by wrong timestamp configuration of some committers.
commits = commits[commits['timestamp'] <= 'today']
initial_commit_date = commits[-1:]['timestamp'].values[0]
commits = commits[commits['timestamp'] >= initial_commit_date]
commits.head()
Summarizing the data
In this section, we group the data to achieve a meaningful visualization with Stream Graphs. We do this by grouping all relevant data of the commits by author and quarters (TIME_FREQUENCY is set to Q = quarterly). We reset the index because we don’t need it in the following.
modifications_over_time = commits[['author', 'timestamp', 'modifications']].groupby(
[commits['author'],
pd.Grouper(freq=TIME_FREQUENCY)]).sum().reset_index()
modifications_over_time.head()
We also do some primitive outlier treatment by limiting the number of modifications to lower than the 99% quantile of the whole data.
modifications_over_time['modifications_norm'] = modifications_over_time['modifications'].clip_upper(
modifications_over_time['modifications'].quantile(0.99))
modifications_over_time[['modifications', 'modifications_norm']].max()
Next, we pivot the DataFrame to get the modifications for each author over time.
modifications_per_authors_over_time = modifications_over_time.reset_index().pivot_table(
index=modifications_over_time['timestamp'],
columns=modifications_over_time['author'],
values='modifications_norm')
modifications_per_authors_over_time.head()
Ugly visualization
At this point, we could already plot the data with the built-in plot function of Pandas.
%matplotlib inline
modifications_per_authors_over_time.plot(kind='area', legend=None, figsize=(12,4))
But it doesn’t look good at all :-/
Let’s bend the data in a way so that it fits into the Stream Graph D3 template!
Treat missing data
The D3.js template that we are using needs a continuous series of timestamp data for each author. We are filling the existing modifications_per_authors_over_time DataFrame with the missing values. That means to add all quarters for all authors by introducing a new time_range index.
time_range = pd.DatetimeIndex(
start=modifications_per_authors_over_time.index.min(),
end=modifications_per_authors_over_time.index.max(),
freq=TIME_FREQUENCY)
time_range
To combine the new index with our existing DataFrame, we have to reindex the existing DataFrame and transform the data format.
full_history = pd.DataFrame(
modifications_per_authors_over_time.reindex(time_range).fillna(0).unstack().reset_index()
)
full_history.head()
Then we adjust the column names and ordering to the given CSV format for the D3 template and export the data into a CSV file.
full_history.columns = ["key", "date", "value"]
full_history = full_history.reindex(columns=["key", "value", "date"])
full_history.to_csv(FILENAME_PREFIX + "modifications" + FILENAME_SUFFIX + ".csv", index=False)
full_history.head()
Because we use a template in this example, we simply copy it and replace the CSV filename variable with the filename from above.
with open("vis/interactive_streamgraph_template.html", "r") as template:
content = template.read()
content = content.replace("${FILENAME}", "modifications" + FILENAME_SUFFIX + ".csv")
with open(FILENAME_PREFIX + "modifications" + FILENAME_SUFFIX + ".html", "w") as output_file:
output_file.write(content)
And that’s it!
Result 1: Modifications over time
Here is the Stream Graph for the IntelliJ Community GitHub Project:
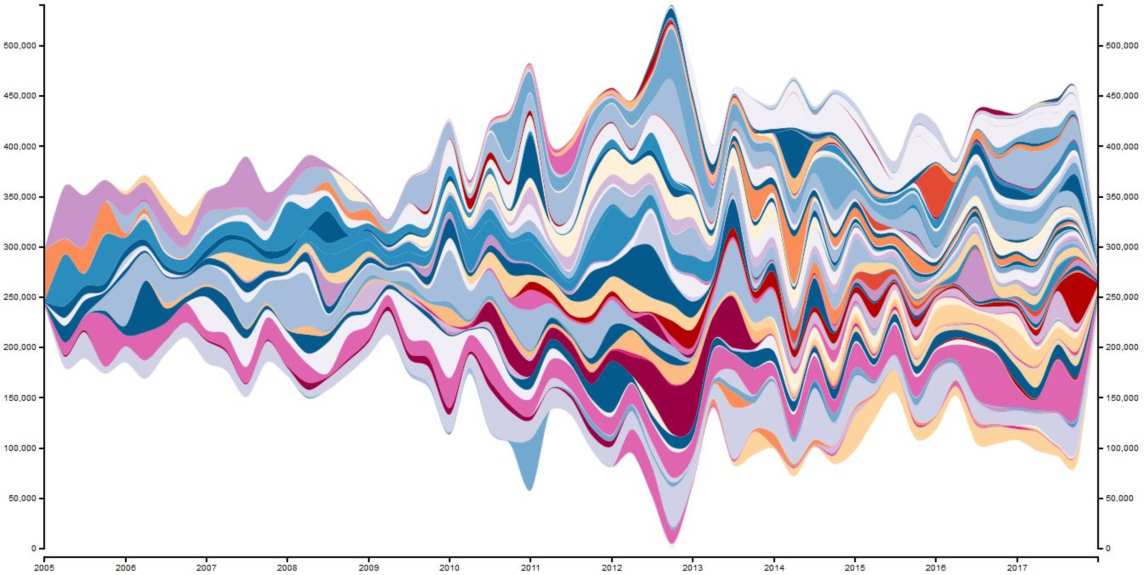
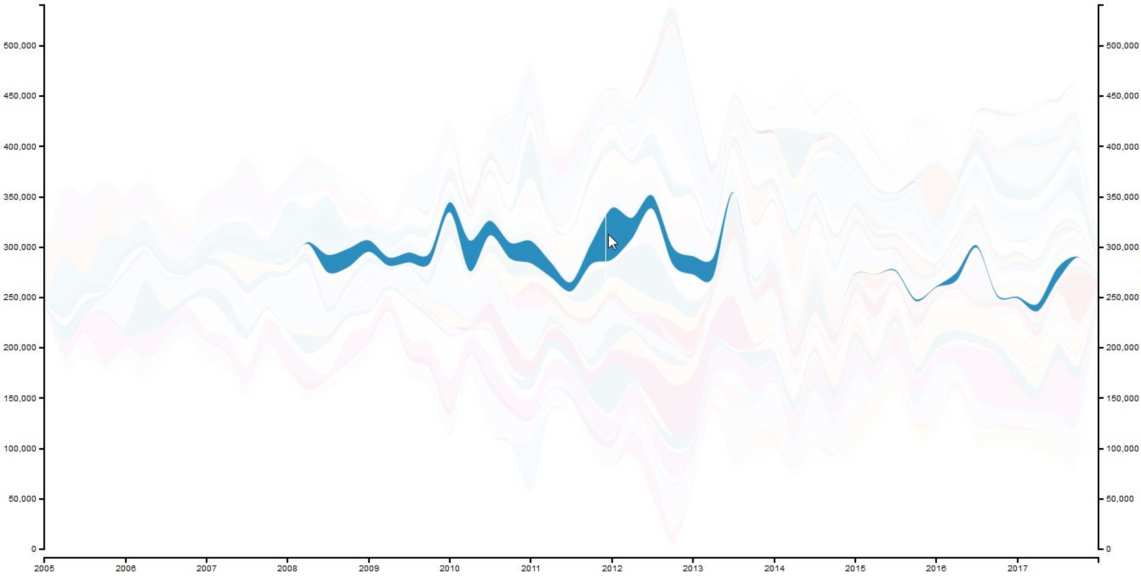
The visualization is also interactive. You can hover over one color to see a committer’s “modifications trail”.
You can find the interactive Stream Graph here (but beware, it loads 0.5 MB of data. This has to be improved in the future).
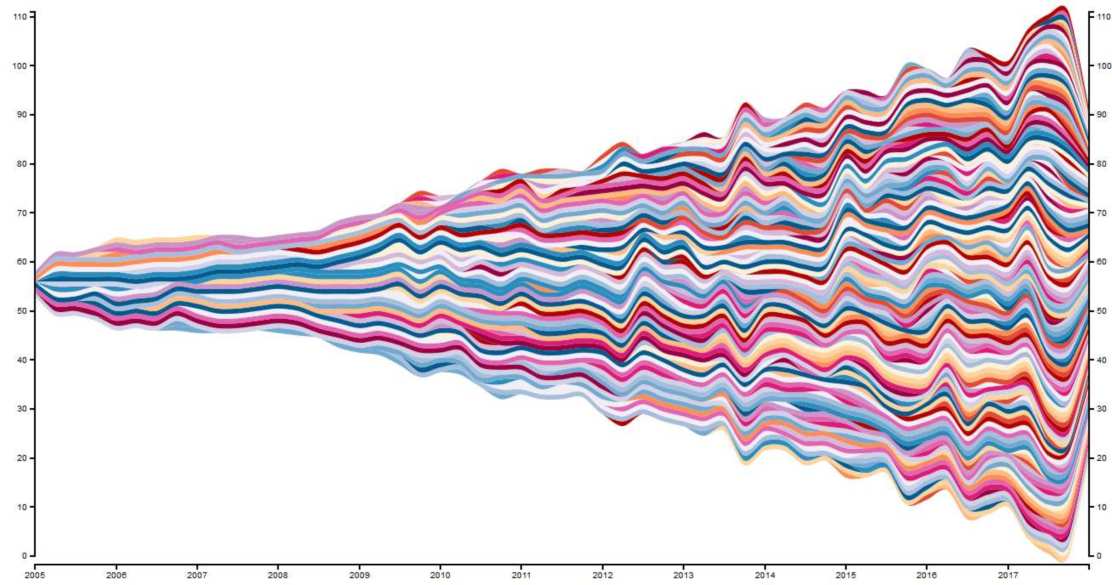
Result 2: Committers over time
Another interesting visualization with Stream Graphs is the number of committers over time. With this, you can see how the developer fluctuation in your project was.
To achieve this, we set the number 1 for each committer that has contributed code in a quarter. Because we are lazy efficient, we reuse the value column for that.
full_history_committers = full_history.copy()
full_history_committers['value'] = full_history_committers['value'].apply(lambda x: min(x,1))
full_history_committers.to_csv(FILENAME_PREFIX + "committer" + FILENAME_SUFFIX + ".csv", index=False)
with open("vis/interactive_streamgraph_template.html", "r") as template:
content = template.read()
content = content.replace("${FILENAME}", "committer" + FILENAME_SUFFIX + ".csv")
with open(FILENAME_PREFIX + "committer" + FILENAME_SUFFIX + ".html", "w") as output_file:
output_file.write(content)
full_history_committers.head()
Here you can see the results – the number of active committers over time:
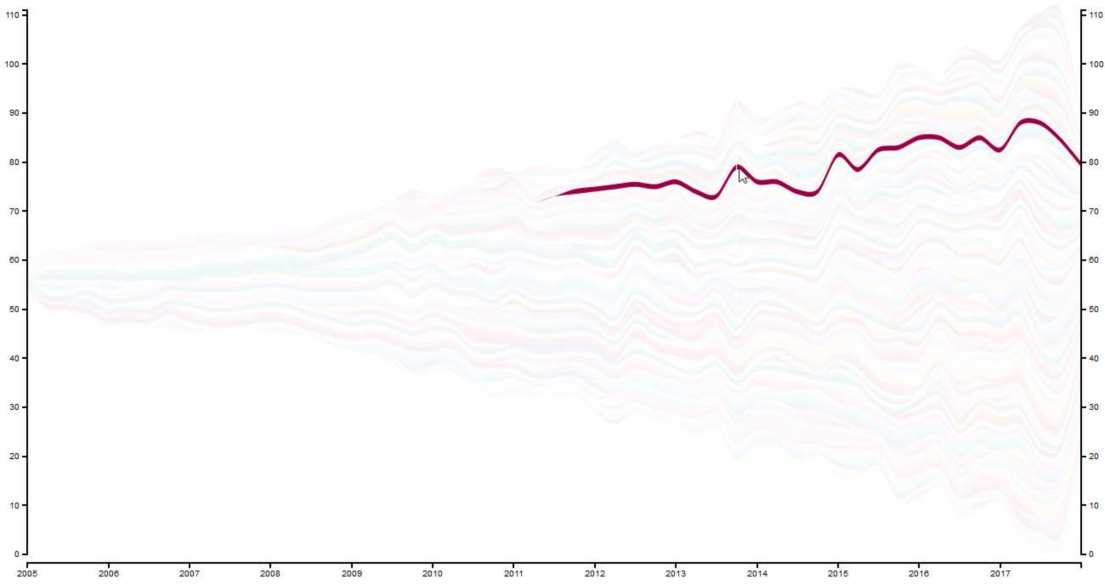
Again, you can have a look at one committer by hovering over the Stream Graph:
You can find the interactive version of it here (again beware, loads 0.5 MB currently).
Conclusion
Stream Graphs are a good visualization technique for chronological data. The interactive feature of highlighting individual is a nice bonus that enables a more detailed view of the data.
Further optimizations should be made regarding the used template: The data format needs a continuous stream of data that leads to huge data files. Additionally, the color schema is hard-coded but should also be dynamically generated.
Overall, Pandas and the Stream Graph D3 template give you a quick way for visualizing Git repository contributions 🙂
This blog post is also available as Jupyter notebook on GitHub.